현 시점의 Java 에서 HashMap 이 어떻게 구현되어 있는지 code level 에서 살펴보겠다
HashMap 의 Field 구성

// key 와 value 값이 저장되는 곳
transient Node<K, V>[] table;
위 필드들 중 핵심은 table 변수이다. Node<K, V> 형의 배열로 이루어진 변수로서 우리가 흔히 key, value 로 저장을 할 때 실제로는 Node<K, V> 형으로 저장되어짐을 알 수 있다. 그렇다면 Node<K, V> 클래스는 어떻게 구현되어 있는지 확인해보자
HashMap 에서 Node<K, V> 클래스
field 값으로 hash, key, value 그리고 Node<K, V> next 를 가지고 있다. 이를 통해 Node<K, V>[] table 이라는 변수가 어떻게 생겼는지 알 수 있다. table 변수는 기본적으로는 배열이면서 각 bin 이 연결된 Node 의 형태를 하고 있음을 알 수 있다.
HashMap 의 put 메서드 구현 방식

먼저 put(K key, V value) 로 자주 사용하는 메서드는 putVal(hash(key), key, value, false, true) 로 putVal 메서드를 호출하게 된다.
이때 hash 함수는 보조 해시 함수로서 다음과 같다
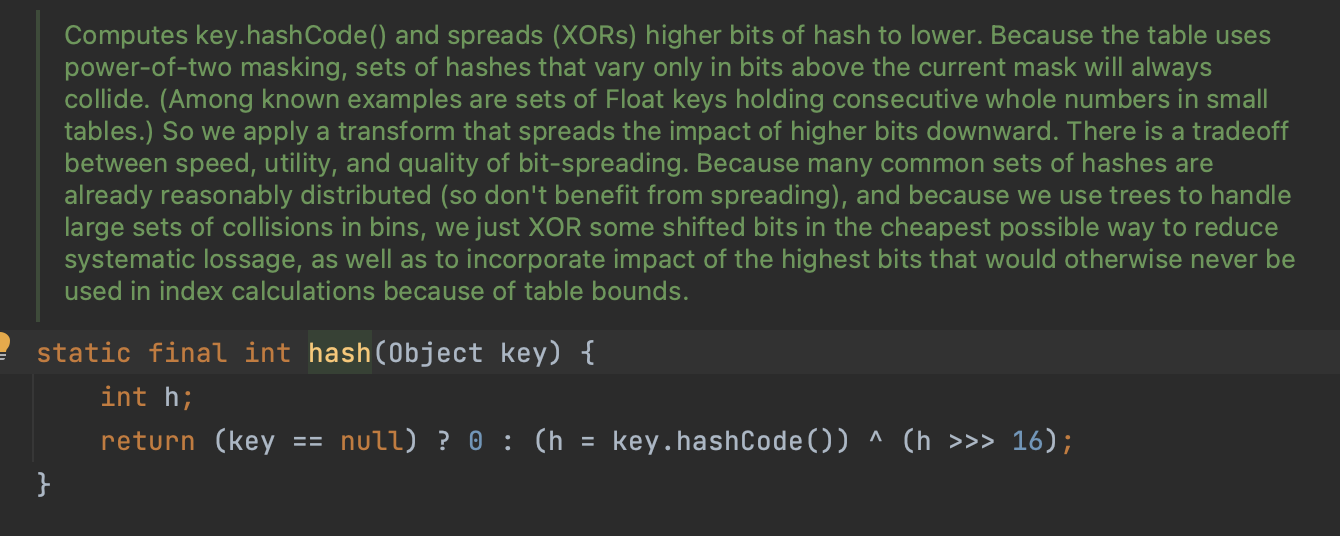
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
hash 값은 위와 같이 null 이라면 0을 return 하고
그렇지 않다면 key의 hashcode 값(이 값을 h라 하자)과 h를 오른쪽으로 16비트 움직인 값과 XOR 연산하게 된 값이다
// 쉬프트 연산자
// x << y : 정수 x의 각 비트를 y만큼 왼쪽으로 이동시킨다.(빈자리는 0으로 채워짐)
// x >> y : 정수 x의 각 비트를 y만큼 오른쪽으로 이동시킨다.(빈자리는 최상위 부호비트와 같은 값으로 채워짐)
// x >>> y : 정수 x의 각 비트를 y만큼 오른쪽으로 이동시킨다. (빈자리는 0으로 채워짐)
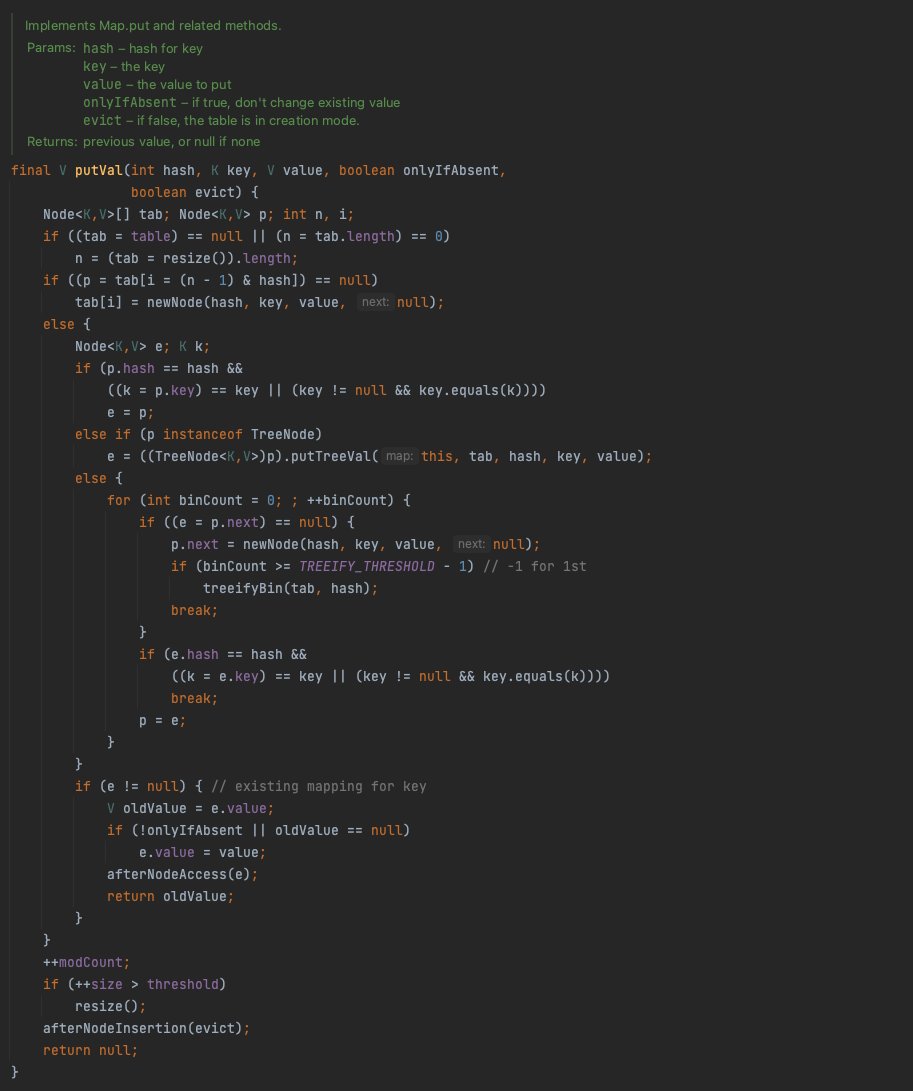
이제 putVal 메서드를 코드 레벨에서 보도록 해보자
final V putVal(int hash, K key, V vlaue, boolean onlyIfAbsent, boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
/*
1. table 이 생성되지 않았거나 생성되었더라도 길이가 0인 경우
위 경우에는 table을 tab 이라는 지역변수로 받고 resize() 과정을 거치게 된다. 또한 이 tab 의 길이를 n으로
저장하게 된다.
*/
if ((tab = table) == null || (n = tab.length) == 0) n = (tab = resize()).length;
/*
2. table 의 index 를 계산하고 해당 bin 에 할당된 Node 가 없다면 Node 를 새로운 Node 를 생성해 할당한다
이 때 p는 table 에서 특정 bin 을 의미한다
*/
if((p = tab[i = (n-1) & hash]) == null) tab[i] = newNode(hash, key, value, null);
/*
3. p=tab[i] 가 null 이 아닌 경우; Node 가 존재하는 경우
*/
else {
Node<K,V> e; K k;
// 3-1. p 에서의 hash 값과 현재 넣으려는 hash 값이 같고 key 값이 일치(물리적 동치)하거나
// equals() 연산이 같다면 e = p 가 된다.
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
// 3-2. p 가 TreeNode 의 instance 인 경우
// Node<K,V> 객체인 e 에 p 를 TreeNode 로 만들어서 할당한다.
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
// 3-3. 해당 bin 에서 next 가 null 일 때 새로운 node 를 할당한다.
else {
for (int binCount = 0; ; ++binCount) {
// 3-3-a. 단 해당 bin 의 개수가 TREEIFY_THRESHOLD-1 이상인 경우
// 해당 bin 을 Linked Nodes 에서 tree 로 변환한다
// e 는 새로운 Node
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
// 3-3-b. 해당 bin 에서 연결된 다음 Node 가 추가하려는 Node 와 같은 경우
// 반복문을 탈출한다
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
// e 가 null 이 아니라면 새로운 value 를 e 노드에 할당하게 된다
// 더불어 기존의 value 를 반환한다
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
// HashMap 에 값을 넣을 때마다 size 변수가 증가하며 threshold 보다 커지게 되면
// HashMap 의 사이즈 재조정이 일어난
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}HashMap, HashSet 의 Key 값이 hashCode() 와 함께 equals() 도 재정의 해야 하는 이유
위 코드를 살펴보면 왜 HashMap 의 경우 hashCode() 메서드와 함께 equlas() 메서드를 재정의 해야만 하는지 알 수 있다. 3-1 주석을 살펴보면 hash 값과 함께 key 의 equals() 값이 일치하는지도 확인하기 때문이다. 따라서 equals() 메서드를 재정의 하지 않은 경우 HashMap 에서 같은 객체를 넣어도 size 가 1개 더 증가하는 일이 발생하게 된다.
https://tecoble.techcourse.co.kr/post/2020-07-29-equals-and-hashCode/
그림으로 이해하기
코드 레벨에서 전반적인 과정을 간단하게 그림으로 표현하면 다음과 같다.